The majority of financial institutions in the world are planning or beginning to implement technological transformation programs to transform traditional core systems to cloud infrastructures. This transformation requires a radical change in application design patterns, from highly coupled monolithic systems based on synchronous interactions and with broad transactional contexts, to component-based systems with very high modularity, very low coupling, based on asynchronous interactions and without possibility of extending transactional contexts outside of the components themselves.
A fundamental problem in these transformations is that the workforce that possesses the business knowledge is accustomed to the traditional system design. In order to take advantage of this workforce, it is necessary to re-skilling the workforce so they can properly design applications with the right characteristic to leverage cloud infrastructures.
One of the most complex challenge in the re-skilling to cloud development, is the definition and management of the non-functional requirements (NFR) of the new cloud systems. In traditional environments, the analyst or developer rarely has to specify or manage NFR when designing or implementing applications. Most of these requirements are managed at the technological platform level. For example, a traditional application designer who implements an integration with another application in the same platform takes the availability of those applications with which he integrates for granted. In traditional platforms, a reactive and not proactive approach is generally followed, that is, it only acts when a response time problem is detected or when a service has failed several times. Furthermore, since most interactions between components are synchronous and through local integration mechanisms (direct calls between COBOL routines for example), integrations are very fast and it is not necessary to worry about the impact of integrations on response times.
This scenario changes when systems are designed for the cloud. The calls to COBOL routines or local java classes become calls to APIs of components that can be deployed in different cloud, the availability of services cannot be taken for granted in the new platforms, and there is no transactional context of the operation end 2 end.
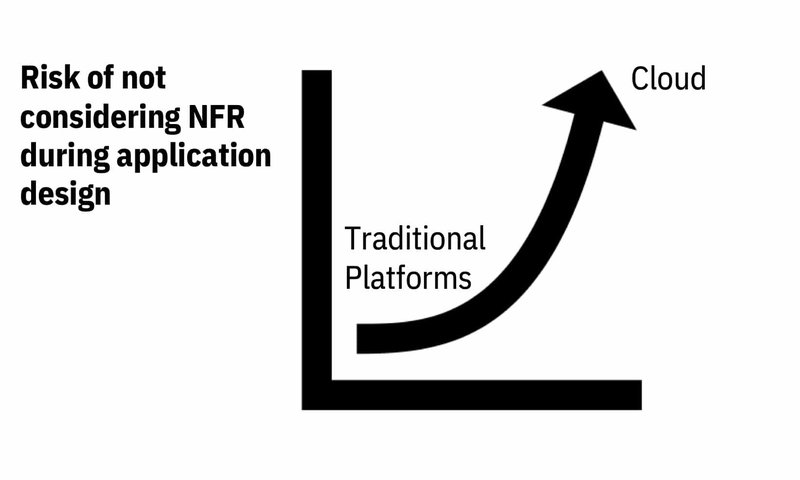
The “Non Functional Requirements Definition Framework” was developed to assist in the transition from developing banking applications for traditional platforms to banking applications for cloud platforms. It is a tool that provides analysts with a guideline to analyze and define NFR, and provides guidelines to application designers and developers on what types of patterns can or should be used according to the NFR defined by the business analyst.
For example, for a component providing a “customer summary” service which is used constantly in digital channels, every time a customer login into the mobile app, the NFR for availability would be determined by the business analyst to be high (as unavailability will have a terrible impact in the customer experience), while a service to maintain the product prices, which is not frequently used by few users, and will never cause a significant business disruption in case of failure, the requirement will be defined to low by the analyst. The framework will them provide the necessary guidelines to the system engineers / developers to design and build the components according to those NFR. In this case, in will recommend that the component with high requirement for availability, cannot depend on other components with lower level of availability and, in consequence should avoid synchronous integrations that could impact the availability of the service if the dependent service fails.
Scope of the NFR
NFRs can be defined for different scopes. For example they can be defined for each application, component, domain, service, etc.
Our recommended approach for the design of banking systems in Cloud is based in the use of Domain Driven Design, and defining the NFRs for each aggregate of the defined domain model.
Structure of NFR Specification Framework
The Non-Functional Requirements for a business solution address those aspects of the system that, whilst not directly affecting the functionality of the system as seen by the users, can have a profound effect on how that business system impacts and is perceived by both the users and the people responsible for supporting that system.
The framework comprises a list of candidates NFR to be specified for each aggregate in the domain model and, for each NFR, it provides:
- Name.
- Description: Description and clear understanding of the NFR.
- Approach: When possible, we use a level based classification (i.e. Golden. Silver, Bronze levels) which really simplify the specification of the NFR; when this is not possible or practical we can ask for specific values (i.e. 5000 Tx/s)
- Guidelines for Analysis: Explanation on how business analysis should classify and identify the NFR for each aggregate.
- Guidelines for Development: Explanation on how system engineers should design and develop the components to meet the expected NFR.
- Implications on architecture: External dependencies to achieve the expected NFR. For example, for a service to have 99,99% of availability we need to rely on technical services with at least this level of availability.
- Reference: links to external resources that may be useful as reference.
The list of NFR usually included in the framework are related to business applications and not in technical platforms. These are the typical ones but the list can be obviously extended:
Run-time NFR
- Availability
- Performance
- Capacity
- Security & Privacy
- Data Integrity / Consistency
- Auditing
- Monitoring
- Scalability
Non-Run-time NFR
- Maintainability
- Portability
- Adaptability
- Multi-tenancy
- Multi-language
- Multi-currency
Example of Non-Functional Requirements included in the Framework
Following are examples from actual projects, of what the NFR Specification Franework can provide. The values provided are representatives and should be adapted to each different scenario.
Availability
Description: This NFR concerns the availability of business capabilities. Business Capabilities are provided via APIs implemented by Application Components that can be a micro-service or other types of components (i.e. in the case of commercial packages), but we´ll considered that an application component implements a ”domain” as described by the application component model (for example, “customer”) and it is represented by an Aggregate (“Customer” Aggregate). In this context we´ll have to establish the availability requirement for each of the aggregate in our solution. For each aggregate, it will be decided, considering the requirements gathered from business, what is the level if availability required.
Guidelines for Analysis: Classify any aggregate according to one of the following levels:
- High Criticality: A business capability provided by an aggregate that is always available. Almost no downtimes are allowed. Suggested measures based on RPO/RTO: 99% availability, recovery time < 30 sec).
- Medium Criticality: A business capability provided by an aggregate that is always available, but some downtimes are allowed under the certain conditions. Suggested measures based on RPO/RTO: 95% of availability, recovery time < 10min
- Low Criticality: Low critical capabilities. Suggested measures based on RPO/RTO: 90% of availability, recovery time < 30min).
Guidelines for Development: In order to achieve the different levels of availability the designer / developers will follow the guidelines:
High Criticality:
- Use a technical platform which require availability level. If there´ is no one available, the NFR cannot be complied
- The components should not depend on other applications with lower level of Availability. If consuming synchronous RestAPI, they should be provided by a component with at least same level of availability, or the integration must include a circuit breaker pattern.
- The application should not depend on external resources with lower level of Availability
- The application design must allow multiple deployments for horizontal scalability.
Implications on Architecture:
- HA / DR models based on the underlying technology.
- Availability provide by the K8s CaaS cluster. Distributed system with redundancy based on having different replicas along the cluster. The K8s policies define how the cluster reacts to Pods unavailability (scaling).
- Availability provided by the VMWare. K8s cluster connected to the VMWare one.
- (vCenter) to manage virtual platform.
- Have to take in account availability of resources not running into the cluster, directly on the IaaS (VMWare), like DBs (if any).
Reference Information:
- Newman, Sam. Building Microservices. O’Reilly Media, 2015.
- https://kubernetes.io/docs/setup/independent/ha-topology/
- https://kubernetes.io/docs/concepts/
- https://github.com/Netflix/chaosmonkey
- https://medium.com/netflix-techblog/the-netflix-simian-army-16e57fbab116
- https://en.m.wikipedia.org/wiki/Disaster_recovery
Performance
Typically expressed as throughput (expressed in concurrent users and number of operations per time of unit) and response time. Performance can also be measure as percentage (i.e. >3 ms at 95% of requests; >5 ms at 99% of requests). We´ll define Performance NFR at a aggregate level and it will establish the expected response time and throughput or any API or event publishing provided access to the aggregate.
Approach: We define performance in a qualitative level than a quantitative level. It could be defined “a priori” performance levels like in “sizes”: gold, silver, bronze. Let’s keep in mind than when we will be dealing with a concrete business requirement this will be the time when we have to make the quantitative finest analysis.
Typical measures used: response time (seconds), throughput (operations/seconds). Quantitative analysis will depend on the specific business requirement.
Guidelines for Analysis. Classify any aggregate according to one of the following levels:
- Gold (High Performance): APIs providing access to the aggregate will have response time lower than 0.5 seconds and throughput higher than 50 operations/second in line with the best potential use of the technical platform.
- Silver (Average Performance): APIs providing access to the aggregate will have response time lower than 1 second and throughput higher than 10 operations/second in line with the best potential use of the technical platform.
- Bronze (No performance). No specific requirement in terms of performance. This is for example for API not exposed to customer or branches, rarely used and supporting non-important business capabilities.
Guidelines for Development:
Gold:
- Choosing a technical platform that can provide expected performance or limit the definition of the Gold level to what is achievable in the plan.
- Provide API responses without dependencies in other services or systems (their response time will add to our response time). APIs supporting the aggregate will not have run time dependencies to external services or resources
- Consider use of event source patterns for micro-service if you have to manage large amount of data
- Ensure component can escalate horizontally.
Silver:
- Develop for a response time considering the response time from the services you´re dependent on.
- Ensure the microservices can escalate horizontally.
- Bronze:
- No specific requirement for performance is needed. So, the implementation guideline doesn’t have any constraint.
Implications on arch:
Performance provided by the technical platform:
- Performance provide by the K8s CaaS cluster. Distributed system with redundancy based on having different replicas along the cluster. The K8s policies define how the cluster reacts to Pods unavailability (scaling).
- Performance provided by the VMWare. K8s cluster connected to the VMWare one (vCenter) to manage virtual platform.
- Have to take in account availability of resources not running into the cluster, directly on the IaaS (VMWare), like DBs (if any)
Reference Information:
- Newman, Sam. Building Microservices. O’Reilly Media, 2015.
- https://cloud.google.com/appengine/docs/standard/java/microservice-performance
- https://github.com/Netflix/chaosmonkey
Security & Privacy
Application Security & Privacy requirement will consider the different level of protection required for the different aggregates. For the purpose of development of business applications, the focus is not set on other security aspects such as physical security, communications security, authentication, etc. The Security and Privacy requirement will be established at an aggregate level, at an entity level, or at value object (i.e. field) level.
Approach: Each component in the target architecture must be classified according to the type of protection required for the data that it managed: same level of protection for all aggregates, different level of protection for different instances of the aggregates, different level of protection for different entities in aggregates, or even at attribute level attributes.
Guidelines for Analysis: For each aggregate, specify whether:
- Gold: It must be possible to establish different level of protection for different aggregate instances and different attributes within any entity in the aggregate. For example, this is required to protect Personal Information (PI) and Sensitive Personal Information (SPI) and implement GDPR regulations.
- Silver: It must be possible to establish different level of protection for different aggregate instances. This is required for example, to protect information about different type of customers (VIP, Employees, etc.) or to provide services to direct channels (a customer can only enquire his/her own account information).
- Bronze: All aggregate will have the same level of data protection. For example, aggregates containing matching rules may require only protection at an aggregate level.
Guidelines for Development: The level of modularity in application architecture in Cloud may be made of hundreds of components (i.e. micro-services) deployed. Things can go horribly wrong security wise when there are many moving parts. We certainly need some law and order to keep everything in control and safe. To make sure we never compromise the security of the overall system is never compromised, the widely recommended approach is to secure invocation of “public-facing” API endpoints of the system using a capable API gateway.
For Gold and Silver, it is recommended to use a data abstraction layer (DAL) (if possible, using some standard tool and not custom developed). The DAL will enable the use “Factory” and “Repository” patterns and should provide the possibility to administer data security policies at an entity and attribute level. The policy administration should be capable of receive the policies by publishing/subscription from domains, those that will manage the permissions, for example, “Customer Product / Service Entitlement Administration”, or “Employee Access Policies Administration”. Bronze level can rely on API level security.
Implications on Architecture:
- Future implementation should secure API endpoints with an API gateway.
- Sometimes, certain endpoints are deemed “internal” and excluded from the security provided by an API Gateway, as we assume that they can never be reached by external clients. This is dangerous since the assumption may, over time, become invalid. It’s better to always secure any API access with an API gateway. In most cases the negligible overhead of introducing an API gateway in between service calls is well worth the benefits.
- Because it is expected a lot of data redundancy / duplication of data across the components, the requirements on privacy and security should be coherent in every component where a data entity / attribute is used. For example, if the financial information of an employee has a higher requirement of privacy than for other customers, this higher requirement will be applied in the customer reference data service but also in any other service providing information about the employee such as customer positions, customer event history, etc. This requires that privacy requirements are defined in a single point of control, probably at the business glossary of the data governance team and spread out to the different domains. This requires that proper data governance processes are out in place.
Ref Info:
- Newman, Sam. Building Microservices. O’Reilly Media, 2015.
- Evans, Eric. Domain-Driven Design: Tackling Complexity in the Heart of Software. Prentice-Hall, 2003.
- https://blog.christianposta.com/microservices/the-hardest-part-about-microservices-data/
- https://github.com/Netflix/security_monkey
Data Consistency/Integrity
Refers to maintaining and assuring the accuracy and consistency of data over its entire life-cycle, to include timeliness of updates and timeliness of availability after an update.
Approach:
- Identify aggregates that require strict (ACID) or eventual consistency with other aggregates
- For ACID (for instance those debiting and crediting money as a part of the double-entry accounting principle), consider than even implementing SAGA at the end will be needed to develop algorithms that are almost a tx. monitor. So, for ACID the modules (components) should expose interfaces that allows tx. propagation (so, no rest) and the arch should support those mechanisms.
- When dealing with strict consistency (ACID) all the required information (data) to achieve the data integrity should be live in the same bounded context of the microservice itself. There is no way to have data across other modules (microservices) because data integrity will be broken.
- For eventual, architecture should support eventual consistency mechanisms that actually are not so easy, as even eventual have to deal with assuring the message delivery and error management.
Guidelines for Analysis: For each aggregate identify transactional consistency requirement with other aggregate. If this happens, the redesing the aggregates because aggregates should be the logical unit to group entities that must have transactional integrity
For each aggregate identify eventual consistency requirement with other aggregate. For each requirement, establish are required level:
- Gold: Consistency achieved immediately (ACID)
- Silver: Consistency achieved in <10'
- Bronze: Consistency achieved within the day (i.e via batch processes)
Guidelines for Development:
For Transactional Consistency Requirement:
- Ensure the technical platform provides transactionality management mechanism
- ensure the entities requiring transactional consistency comes together in the same aggregate. If not, report the issue to business analysts.
For Eventual Consistency:
- Select the platform service that support the require speed of event propagation.
- The components managing the aggregates must ensure that the consistency is achieved. It means tracking down that all events have been handled and / or implementing background processes that checks the consistency of aggregate entities with the external entities that must be consistent with.
Implications on arch:
Following some architecture styles such as micro-services implies supporting just eventual consistency, no ACID features. To achieve transactional consistency, all entities must be included in the same aggregate.
Ref Info:
- Newman, Sam. Building Microservices. O’Reilly Media, 2015.
- https://blog.christianposta.com/microservices/the-hardest-part-about-microservices-data/
Auditing
Capability to trace and identify the source on any changes in the aggregates of the domains.
Approach: Predefined levels Gold, Silver and Bronze.
Guidelines for Analysis:
For each component, identify the required level.
- Gold — Full traceability of any change in any element of the aggregate must be provided. Each change in the aggregate is tracked with a recorded Action, which trace the source of the change. Include Enterprise Identifiers for enterprise wide traceability. Ability to recover the existing and resulting value of the aggregate for a specific action.
- Silver — Similar to Gold but without the ability to recover the existing and resulting value of the aggregate for a specific action.
- Bronze — Traceability at an action API / Event level, but without trace of specific changes in the aggregates with the Events /API
Guidelines for Development:
- Establish mechanisms for traceability at: Code level (for tracing if any problem).
- Establish mechanisms for traceability at: Business Events.
- Establish mechanisms for traceability at: Data level. To audit data access (this could be at the DB level).
- API calls and actions related to event subscriptions.
- Consider internal vs external Event publishing mechanism for traceability.
Implications on architecture:
- Auditing design should ensure that all the user and system actions are thoroughly recorded and stored properly so that it’s to trace and identify the exact sequence of events that happened in the system.
- It’s also important to store the data change (old data vs. new data) along with the timestamp and user details that induced the change.
- The Architecture should provide a centralized log manager capability so the different audit logs in the microservices are consolidated to provide e2e auditing of a request involving several microservices.
- See Security/Privacy requirements. Use the DAL (Data Access Layer) mechanism to provide data level traceability.
Ref Info:
- Newman, Sam. Building Microservices. O’Reilly Media, 2015.
- https://microservices.io/patterns/observability/audit-logging.html
- https://docs.aws.amazon.com/aws-technical-content/latest/microservices-on-aws/auditing.html
Monitoring
Pro-active monitoring of application’s health can go a long way in ensuring the availability of the system and tackle any unexpected scenarios in production. There are multiple levels of monitoring including application layer monitoring, database layer monitoring, application usage monitoring, error monitoring, trial monitoring, event monitoring and alert monitoring.
Approach:
Monitoring guidelines for the code development. Probably should be the same regardless the type of functionality. Just to activate different levels of traces based on the type of analysis (and severity).
Guidelines for Analysis:
From a functional point of view, we will be focused in the processes of reporting, gathering and storing data to be monitored. Maybe each application could have different needs about monitoring, but considering the functionality of each aggregate, we have to define what is going to be required to monitor on each one.
For instance, if our aggregate accepts user registrations, a standard metric might be how many were successfully completed in the last hour. But if we have another aggregates to deal with taxes-preparation, the microservice might record context-specific events such as form validation.
The key point is to keep the necessary information to allow development teams and the organization to understand the functional behavior of the system. If peak-volume form validation typically occurs 1,000 times an hour, and suddenly that throughput drops to 500 over the last two hours, that anomaly could be an indication of a problem. There is no a good practice to say: “I want to monitor everything because this is not realistic”.
Guidelines for Development:
Establish mechanisms for traceability at:
- Code level (for tracing if any problem).
- Business Events: API calls and actions related to event subscriptions. Consider internal vs external Event publishing mechanism for traceability.
- Data level. To audit data access (this could be at the DB level).
Implications on arch:
Cloud Banking Architectures are systems that may have lots of more “moving parts” than the existing monoliths. As such, when implementing a cloud architecture, it becomes very important to have extensive system-wide monitoring and to avoid cascading failures.
It’s important to design the architecture in a way the data points required for the above-mentioned monitoring are easily available.
Ref Info:
- Newman, Sam. Building Microservices. O’Reilly Media, 2015.
- https://www.oreilly.com/learning/monitoring-a-production-ready-microservice
Scalability
These requirements specify how the system is able to scale up to handle additional work load. Factors used to specify scalability typically include increase in number of users, number of transactions, network traffic, and size of data managed.
Approach: Predefined levels Gold, Silver and Bronze.
Guidelines for Analysis:
- Define the data storage requirements in term of number of instances of the aggregates. This storage should be calculated to handle the common use. Frames with less activity, frames with medium activity and frames with top activity.
- Define the requirements in term on concurrent API invocation. Same as above, frames with expected use.
- Based on number of expected events published / subscribed in a unit of time (i.e. per minute) also considering frames for activity determine the level of the system (gold, silver, bronze) to handle events.
Guidelines for Development:
Based on level defined for the component (gold, silver, bronze), could be establish a level for dependencies.
- For gold component, full scalability is going to be required, so most of the dependencies (potentially all) should be avoid getting this full scalability.
- For lower levels some dependencies should be allowed.
- The development should consider the capability to increase the number of users, transactions and so on without change any code. There should be no restriction inside code logic to be able to handle the potential increase of additional work load.
Implications on arch:
- Design should be implemented thinking about elastic scalability of the system.
- The underlying technology should provide this elastic scalability in order to handle additional work load.
- The platform should be able to handle in an elastic way number of users, number of transactions, network traffic, and size of data managed.
Ref Info:
- Alagarasan, Vijay. “Seven Microservices Anti-patterns”, August 24, 2015.
- Newman, Sam. Building Microservices. O’Reilly Media, 2015.
- https://github.com/katopz/best-practices/blob/master/best-practices-for-building-a-microservice-architecture.md
- https://developer.ibm.com/tutorials/cl-ibm-cloud-microservices-in-action-part-1-trs/
- https://developer.ibm.com/tutorials/cl-ibm-cloud-microservices-in-action-part-2-trs/
- https://www.nginx.com/blog/microservices-at-netflix-architectural-best-practices/
Non-Run Time NFR
Maintainability
The maintainability requirement establishes the maximum allowed time for defect fixing and the frequency of new releases.
Approach: Predefined requirement levels per aggregate (Gold, Silver, Bronze).
Guidelines for Analysis: Identify the level of Maintainability required for each aggregate.
For Correctives we suggest the following levels:
Gold:
- Incidences in Productions must be able to be fixed in less than 2 hours.
- Ability to restore previous versions of the component if a defect is found in a new release if the fix cannot be applied in the 2 hours deadline.
Silver:
- Incidences in Productions must be able to be fixed in less than 5 hours
- Ability to restore previous versions of the component if a defect is found in a new release if the fix cannot be applied in the 5 hours deadline.
Bronze:
- Incidences in Productions must be able to be fixed in less than 2 days.
- Ability to restore previous versions of the component if a defect is found in a new release if the fix cannot be applied in the 2 days deadline.
For Evolutives, following levels are proposed:
Gold:
- Ability to deploy a minimum of 1 release every 2 weeks.
Silver:
- Ability to deploy a minimum of 1 release every month.
Bronze:
- Ability to deploy a minimum of 1 release every 3 months.
Guidelines for Development:
- Development Modularity and Module Size are the key for maintainability and agility. Every dependency increases the testing time and the operational risk. Components with more functionality supports, requires also much more testing and impact analysis.
- It is quite important to consider the size of the component. As bigger the component, more complex its implementation will be, and more complex its maintainability. So, whenever it is possible, keep the components as small, as you can.
- Another vital point to have in mind is the relationship between components (up & down-streams):
- If a conformist relationship is established, we have to be aware that upstream team has no motivation to support the specific needs of the downstream team. So, the team conforms the upstream model as is
- if a customer-supplier relationship is chosen, the supplier must provide what customer needs. It is up to the customer to plan with the supplier to meet various expectations, but in the end the supplier determines what the customer will get and when.
- Compatibility with previous versions: versioning should be part of our architecture and no just some kind of afterthought. Just for external API’s it is already important but with the fine mesh of interconnected services we are defining in our architecture. Some strategies should be implemented to achieve correct versioning, we suggest “adapter based versioning” because it is the more robust and elegant solution. This solution is based on the adapter design pattern and taking advantage of the loosely coupled nature of microservices and protocol version, just return a completely different object.
Implications on arch:
- The CI/CD must include dependencies control. Every API or Event consumed must be declared and tracked against changes. If a provided API or event changes, the CI/CD will trigger an impact analysis and alerts with the consumers to avoid propagation of failures.
- No API or event consumptions should be allowed (at least in critical components) without an anti-corruption layer that minimizes the risk of failure in the case of changes in the consumed resource.
- To meet the NFR it´s key to have the proper team with the proper skills and availability. However, design aspects are critical to achieve such requirements.
Ref Info:
- Newman, Sam. Building Microservices. O’Reilly Media, 2015.
- Fielding, Roy. “Architectural Styles and the Design of Network-based Software Architectures”. PhD diss., University of California, Irvine, 2000.
- Alagarasan, Vijay. “Seven Microservices Anti-patterns”, August 24, 2015.
- https://github.com/katopz/best-practices/blob/master/best-practices-for-building-a-microservice-architecture.md
- https://www.nginx.com/blog/microservices-at-netflix-architectural-best-practices/
Portability
The most common use of these requirements is to specify a certain degree of cross platform compatibility, which typically drives the selection of more open languages and protocols in the solution design.
Approach: Predefined levels Gold, Silver and Bronze.
Guidelines for Analysis: for each component, identify the required level:
- Gold: Ability to deploy in any CaaS Provider (Cost Reduction Driver), including on-prem and off-prem.
- Silver: Ability to deploy in any OpenShift PaaS, including external Cloud providers.
- Bronze: Only require to be deployed in the Internal PaaS of a specific vendor (Openshift).
Guidelines for Development:
Gold:
- Ensure Independence from other component and technical resources other than the self-contained in the Container.
- Do not consume internal API
- Follow the 12-factor (or any other design principle for Cloud Native).
Silver: Same as Gold but allow the use of platform services, but only when the resources are provided natively by the OS.
Bronze: no special requirement for portability (not recommended).
Implications on arch:
The most common use of these requirements is to specify a certain degree of cross platform compatibility, which typically drives the selection of more open languages and protocols in the solution design.
Consider portability requirements, at a level of component, the ability to deploy a component in a single Cloud or in different Clouds.
Ref Info:
- Evans, Eric. Domain-Driven Design: Tackling Complexity in the Heart of Software. Prentice-Hall, 2003.
- Newman, Sam. Building Microservices. O’Reilly Media, 2015.
- https://github.com/katopz/best-practices/blob/master/best-practices-for-building-a-microservice-architecture.md
Adaptability or Extensibility
This is also called to as extensibility, and typically refers to the ease of extending the system design to cover additional functionality at a future time. This additional functionality may or may not be planned at the time the solution is designed.
Approach: Predefined levels Gold, Silver and Bronze.
Guidelines for Analysis: Based on predefined levels, the business analyst should categorize the components according to those levels. The rules which should follow are the following:
- Gold: a key component which is expected to have additional functionality in a near future.
- Silver: component with potential changes regarding additional functionality in future, but those potential changes are not clear at the moment of designing the component.
- Bronze: no need for extensibility detected in future. So, no constraint designing the component.
Guidelines for Development:
Based on level defined above, the development should implement the code of the component following the “O” of the SOLID Principles. That is: we should be able to extend a class’s behavior (applies also for microservices) without modifying it. Or in other words: “software entities should be open for extension, but close for modifications”.
- Gold: this component should be prepared to support extensions. It a must.
- Silver: this component should be ready to support extension. It is a should.
- Bronze: no constraint in implementation of the component (not recommended).
Implications on arch:
When we were designing an implementing arch we have to keep in mind that the final system designed and implemented should be easy to extend an be easy to add new functionality in a near future. So, as we said before, the solutions should be easy to extend and close to changes.
Ref Info:
- Evans, Eric. Domain-Driven Design: Tackling Complexity in the Heart of Software. Prentice-Hall, 2003.
- https://github.com/katopz/best-practices/blob/master/best-practices-for-building-a-microservice-architecture.md
Multi-Tenancy
It is the capability to run and support business capabilities for different business organizations
Approach: when we are dealing with the design of an aggregate we have to think about whether this aggregate is going to be just for an organization or may serve, now or in the future, to support other organizations.
Guidelines for Analysis:
- Gold: A single instance of the aggregate will support more than one business organization.
- Silver: A single instance of the aggregate will support just one business organization, but I can use multiple instances, each of them supported a different organization.
- Bronze: The aggregate only has to support one organization
Guidelines for Development:
- Gold: avoid any kind of hardcoded. All parameters should be externalized and configurable. The data model should support several organizations in the same data model with proper data segregation mechanisms
- Silver: the data model should support different organizations in different instances of the module. No hardcodes are allowed.
- Bronze: the data-model is just for the organization.
Implications on arch:
Balance with principles of simplicity, the principle of solving concrete (and not future) business problems, the principle to develop small components… etc. If may do sense if there´s some multi-entity or multi-country requirement, because this would support such requirements.
Ref Info:
- https://developer.ibm.com/articles/cl-multitenantcloud/
- https://ayende.com/blog/3530/multi-tenancy-approaches-and-applicability
Multi-Language
Multi-language is when something is expressed in two or more languages. Multilanguage is also referred to as multi-lingual. When a system or component has the ability to “speak/understand” in more than two languages he is said to be multilingual.
Approach: predefined levels Gold, Silver and Bronze, so it has to be an analysis where multi-language support is going to be needed.
Guidelines for Analysis:
- Gold: An instance of the component supports several languages (usually for customer facing business capabilities)-. When dealing with this feature, the component is going to have constraints, like avoid any hard-coded regarding the language.
- Silver: An instance of the component supports only one language, but this language can be set up in the configuration. I can use several instances of the module (component) to support several languages.
- Bronze. No multi-language support.
Guidelines for Development:
- Gold: support multi-language. Any kind of hard-coded regarding the language should be avoid. Multi-language words should be identified using a unique identifier. There is going to be need the building of some kind of dictionary/mechanism with all the translation according the language selected by the user.
- Silver: same as above (gold), but less restrictive. Maybe the capability of multi-language is a “nice to have” in the component, but it is not a must in the business capabilities of the component
- Bronze: nonsupport for multi-language There is no restriction regarding language, so the implementation of the component should be simpler, it doesn’t have to deal with files with configuration to make the translation and so on.
Implications on arch:
It has to be an analysis where multi-language support is going to be needed, because it could not be sense in terms of cost/effort for some components. For instance, for back-office components. But on the other hand, it could be a must when we were dealing with components exposed to the final customer (mobile, web…)
Ref Info:
- https://en.m.wikipedia.org/wiki/Internationalized_domain_name
- https://en.m.wikipedia.org/wiki/Transliteration
Multi-Currency
Multi-currency system refers to the business capability that enables the software trading in multiple currencies, which facilitates buying and selling internationally.
Approach: Predefined levels Gold, Silver and Bronze, so it has to be an analysis where multi-currency support is going to be needed.
Guidelines for Analysis:
- Gold: An instance of the component supports several currencies. When dealing with this feature, the component is going to have constraints, like avoid any hard-coded regarding the currency. It has to be considered multiple conversions between multiples currencies, so it could apply additional business rules.
- Silver: An instance of the component supports only one currency, but this currency can be set up in the configuration. I can use several instances to support several currencies.
- Bronze. No multi-currency support. We have to be sure that this component it doesn’t have any constraint regarding currency. So, business logic could be simpler.
Guidelines for Development:
- Gold: no hard-coded allowed regarding currency. Invocation to additional business rules could apply.
- Silver: same above (gold), but with a little more of flexibility.
- Bronze: no constraints when dealing with currency. More freedom to design and implement the requested business capability.
Implications on architecture:
When we design a aggregate, it is going be a need if this aggregate is going to be able to deal with multiples currencies. Maybe it makes sense for aggregates which are dealing with international markets (buying funds, mortgages in foreign currency…), but maybe it doesn’t make sense for aggregates which are dealing just with local currency.
Ref Info: